For those new to the file systems space, the concept of a stream is likely to be new. While NTFS has implemented and made streams available since Windows NT first shipped in 1993, even today this is a feature that is seldom used by application programs. However, with the addition of new APIs in the Win32 programming interface for detecting and enumerating the presence of streams (FindFirstStream and FindNextStream APIs were introduced with Windows Server 2003), it is increasingly likely that these APIs will become more common in future applications.
For those of us involved in kernel level file systems programming, it is important to understand the concept of a stream because streams are integral to the programming interface such as the Filter Manager. For example, Filter Manager explicitly uses a concept of a stream context rather than a file context. Indeed, file contexts are not supported in the Filter Manager as of the date this article was written. However, we expect support for file level contexts will become possible in future versions of the Filter Manager.
Historically it has been useful to associate additional information with a file in a way that was transparent to the applications using the data. Ideally, such an association becomes just one more part of the file. So, for example, if a user copies the file, the additional information is moved along with the user's data portion of the file. Early examples of such ancillary information include the resource fork, which is an attribute that was added on the Macintosh in order to associate a specific application with the given data file. In Windows that association is traditionally done based upon the file name (its extension). However, in the Macintosh world it was an inherent part of the file, which meant two files using the same extension name could actually invoke different applications.
In OS/2 Microsoft and IBM added an application-level attribute mechanism known as extended attributes. In keeping with its shared OS/2 heritage, when Windows NT 3.1 first shipped, all three of its native read/write file systems supported extended attributes. NTFS and HPFS had native support in the file structure itself, while FAT uses a hidden file in the root directory for tracking extended attributes. Even today the FAT file system code in the IFS Kit (and now the WDK) includes vestiges of the code needed to support extended attributes in FAT-12 and FAT-16 formatted file systems. The FAT-32 format, however, does not support extended attributes.
The design of NTFS included a modular concept that files were containers of one or more streams. Each stream could then have a collection of attributes that described the characteristics of the specific stream. For NTFS, one benefit of this model was that they could support Macintosh resource forks for use with Services for Macintosh. A careful review of the CDFS source code - also in the IFS Kit and WDK - shows there is support for Macintosh resource forks there as well. This modular concept also provided a generally extensible mechanism for allowing applications and other system components to associate information with the file.
One possible motivation for this might have been the work that was being done in the same timeframe by the OLE team. At that time, the OLE team was embedding a file system within the file to allow transparent support for embedding data elements from different applications. While this scheme was not transparent to applications, it was wrapped in libraries that applications could use, which made it appear transparent. While we're not certain if this was the motivation, it would be a strong temptation for a file systems developer to look at ways to add support for this sort of separation directly at the file systems layer. Indeed, during the development of Windows 2000, there was a short-lived attempt to implement structured storage by using the NTFS streams mechanism.
Having provided a basic motivation for streams, we still have not really described what they are conceptually. The following diagram (See Figure 1) attempts to demonstrate one conceptual model for how a single file might contain more than one stream of data. While loosely based upon the NTFS model, we do not claim this is the NTFS model, nor should the reader infer anything about how NTFS or any other file system implements streams.
|
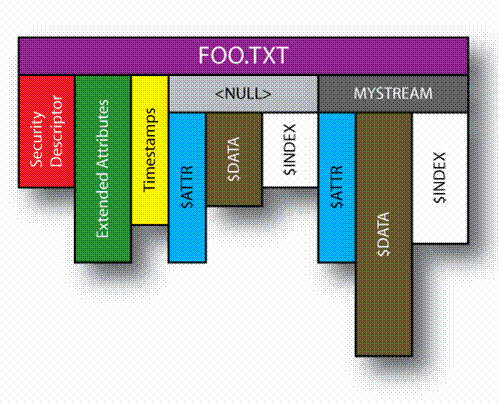
Figure 1 - Conceptual Model for Streams |
Thus, conceptually a single file consists of multiple distinct components. Some of these are attributes that apply to the entire file. For example, this might include the security descriptor, the extend attributes list for the file, and the timestamps on the file. A stream then has a name, with the default name being a zero length string such as the NULL name used in the figure above. Alternate streams have a non-zero length string name. Each stream name is unique, but there may be many different streams. The file system is responsible for placing any restrictions on the name, such as the size of the stream name. An individual stream then has its own associated data attribute. In the figure above we used the name $DATA because that's easiest when we start explaining the naming used by NTFS. Because a stream has data associated with it, the file system must also maintain additional information about the stream such as its location information, the size of the data elements, any extant lists, and bitmaps or other control structures that might be unique to that given stream.
Streams can be used to store almost anything. Because they are just another element of the file, applications can either ignore the stream or use them if and when they are present. System utilities can be constructed to preserve streams. For example, the Win32 API CopyFileW is aware of the streams of files and copies those streams. Similarly, the Win32 Backup API is aware of streams and "packs them" into a single flat byte stream that consists of <stream header>+<stream data>+ etc., which allows the entire file contents to be backed up in a fashion that is transparent to the backup application. Prior to the introduction of the FindFirstStream API in Windows Server 2003, the backup API was the documented way to learn about the existence of streams. In this context "documented" means there was a Microsoft Knowledge Base article describing how to use the backup API to find the streams of the file.
In order to allow applications to open a specific stream, NTFS extended its name support to include the use of the colon (':') character to separate the name of the file from the name of the stream. This is similar to how the backslash ('\') is used to separate the name of the directory from the name of the file. FAT does not support the use of colon (':') in its file names, and thus it is not possible to open streams on a FAT file system without receiving a program error. Since other file systems do support streams, an application programmer should determine streams support either by:
-
Attempting to open a file stream.
-
Querying the file system characteristics and checking for the FILE_NAMED_STREAMS attribute.
Application programs should not use the name of the file system since this will create a persistent problem that causes application compatibility issues. Other file systems besides NTFS support streams and the stream concept.
An application that is not "stream aware" will normally open the file by name. This application then obtains the default data stream. Thus, opening the file foo.txt is the same as opening the stream foo.txt::$DATA (that is, the data attribute of the stream with a NULL name). However, if you try this with many applications you will find that it fails - not because streams don't work right, but rather because applications that are not stream aware may try to validate the existence of the file by looking in the directory. Since the directory does not list the streams of a file, the application will determine the name specified is not present. An example of this behavior is shown in Figure 2 using the command line.
|
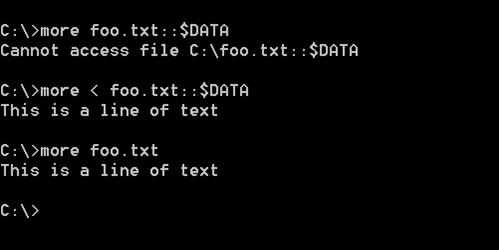
Figure 2 - Variations on Stream "Awareness" in Apps |
Note that using the more utility with the fully qualified name, including stream suffix, does not work, but redirecting the input from the name does work properly, as does accessing the file without a stream identifier. How a specific application behaves when there are streams on a file depends on the implementation of the specific application program.
Using the filespy utility we were able to "see" that the real issue for the more utility is that it attempts to validate the file in the directory. The relevant part of the trace for the first command is shown in Figure 3.
|

Figure 3 - Watching "More" with FileSpy |
Notice that it is calling IRP_MJ_DIRECTORY_CONTROL (IRP_MN_QUERY_DIRECTORY) with FileBothDirectory Information and the return is STATUS_NO_SUCH_FILE. While not clear in the trace, we assert that this is because the file it is seeking is, in fact, the full name including the stream portion. It does not work the same way if we do this via indirection.
It turns out that the best utility for accessing streams is the lowly utility notepad. Instead of interrogating the directory, the notepad determines the presence or absence of streams by attempting to open the named object.
Figure 4 is a simple example that creates a single file with two data streams using the command line utility.
|
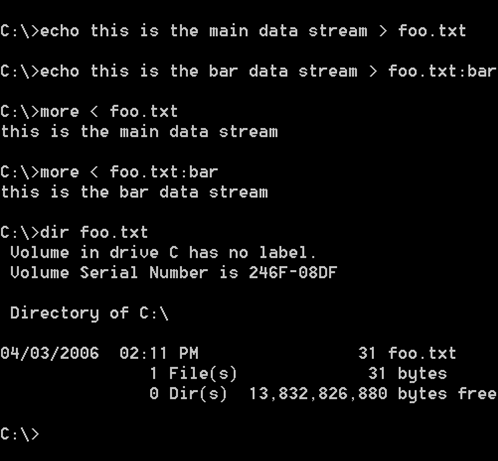
Figure 4 - One File...Two Streams |
The first line creates the default data stream "by default" since it is not specified. The second line creates a stream called bar that is named. Next we retrieve the contents of the respective streams. Finally, we note that the directory entry only reports the size of the data in the default data stream.
Now that we've described streams on files, it is only a small leap to note that NTFS also supports alternate streams on directories. The ability to embed information within the directory that does not show up in a listing of the directory contents is a terrific way to store ancillary directory information such as directory-level policy for a backup program. In NTFS the default data stream for a directory is not available for use since it is used to store the actual directory contents.
When an application opens a file, the Windows OS creates a corresponding FILE_OBJECT to represent that specific open instance of the file. With the introduction of streams, the names of the data structures do not change, but how they are used does change. This concept can be confusing for those just starting their work in the kernel environment.
Traditionally, a file system associated a specific file state with the file object using the FsContext field of the FILE_OBJECT. This is often referred to either as the File Control Block or the Stream Control Block. The latter name reflects the support of streams as a first-class entity within the file system. This is important because normally (e.g., in a filter driver) we associate two FILE_OBJECTs together if they have the same FsContext pointer value. However, if the underlying file system supports streams, then these two values really represent the same stream and not the same file.
To demonstrate our point, Figure 5 graphically demonstrates one possible model for organizing file system data structures when a file system actually does support streams.
|
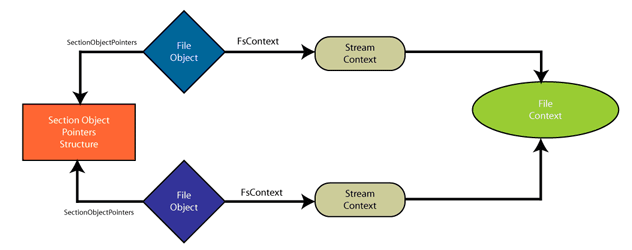
Figure 5 - Model for Organizing Data Structures for Stream-Supported File System |
For a file system filter both the SectionObjectPointers and FsContext values are visible from the file object, but the association between the Stream Context and File Context is
entirely internal to the file system. Thus, there is no simple way to associate these.
One way to achieve this would be to obtain a file-level attribute - something that is reported to be the same for all streams of a given file. For example, with NTFS we generally use the File ID because this 64-bit value is unique for a given file on a given volume. If we find two streams that report the same File ID value, we know they represent the same file even if the FsContext fields are different. In this case we know these are different streams of the same file.
However, not all file systems support this feature. For example, the CIFS/SMB Redirector does not return the same File ID for different streams of the same file even if the remote file system is NTFS because the redirector generates such a File ID. Thus, trying to associate different streams with the same file via redirector is more of a challenge - and one beyond the scope of this article.
Unfortunately, this means there is not a general purpose solution for this problem. While Filter Manager promises a solution in a future release, we anticipate that support will likely be restricted to future Windows versions, which makes this an issue that will eventually "go away" but is likely to remain with us in the foreseeable future.
Having described the basic mechanism of streams and how they are viewed from the kernel file system/filter driver level, we thought it would be useful to provide additional motivation for use of streams. At the present time, searching for information about streams and their uses in NTFS is a bit discouraging since almost every article talks about how streams are potential security hazards. The very features that make streams useful (the fact they aren't immediately visible, they don't affect the reported size of the default data stream, etc.) also makes them potential security hazards for users not expecting streams to be present. Hopefully, future versions of Windows will include utilities to monitor streams (e.g., right-click to "enumerate the streams on this file"), which might be a useful extensions to Explorer.
For now, listed below are a few existing uses of streams:
-
Internet Explorer associates zone information with a given file. This information tracks the origin of the file when it is downloaded from the Internet so subsequent attempts to access the file can take appropriate safeguards.
-
Internet Explorer in Windows 2000 embedded a thumbnail for graphic images to speed up rendering of directory contents. In Windows XP this thumbnail was moved to a separate file for performance reasons. In the process, this change created an interesting information exposure security vulnerability.
-
Services for Macintosh continue to use streams for resource forks even though SFM usage is deprecated these days.
-
SQL Server 2005 stores database information in streams.
However, it isn't terribly difficult to construct other possible usage scenarios for streams. A few examples of possible usage scenarios are listed below.
-
An encryption driver could store "encryption header" information in a separate stream from the data, which would preserve the original data size and data layout.
-
A partially resident file might have additional control information, such as through an HSM product that describes what is or is not present in the file.
-
A file data validation driver could store checksums on blocks of the file in a separate data stream. Such checksums can detect end-to-end data failures, which is similar to a technique used by Exchange to validate its own data.
-
Digital Rights information could be associated with the file.
-
A backup filter could track individual blocks of a file that have been changed since the last backup, allowing for only incremental updates to be captured to a backup set.
-
An auditing application might store auditing policy in a separate stream such as a directory level stream.
-
Application programs might find streams useful as a means of providing "backward compatibility" by storing extended information for newer versions in alternate data streams.
Streams provide a highly useful, albeit obscure, mechanism for associating information with the data contents of a file. With the creation of Win32 APIs, and the advent of more file systems that support them in future Windows releases, we expect to see more uses of streams in the future.


 Post Your Comment
Post Your Comment